DB2 pureScale rebuild TSA Resources
In order to be a successful DB2 pureScale DBA, one has to learn how to diagnose and fix TSA. Though, this is not necessary but it will help to fix cluster in case you run into situation when you get messages like "SQL1517N db2start failed because the cluster manager resource states are inconsistent." or something like "Cluster manager resource states for the DB2 instance are inconsistent. Refer to the db2diag.log for more information on inconsistencies." When you try to repair resources using command db2cluster -cm -repair -resources and you may receive an error stating that repair resources failed and "Refer to the db2cluster command log file. This log file can be found in /tmp/ibm.db2.cluster.*."
If repair resources fail which was supposed to get you out of trouble, it becomes an issue for how to fix the error. The first course of action to open a PMR and get through all procedures to be done before an exact cause is found.
Fixing a db2 pureScale cluster is nothing but knowing something about TSA. DB2 has provided all necessary commands to rebuild all resources. This should be done when you have all DB2 member hosts and CF hosts are available and online. Do not attempt to drop and try to rebuild resources if any of the hosts in your pureScale topology is down.
Note: Two very important files needed in pureScale recovery or rebuilding of resources are: 1. global.reg – which is normally in /var/db2 folder. Each host has its local registry file and you should make efforts to regularly backup /var/db2/global.reg from each hosts. 2. instancedef.reg – which is a shared file common to all hosts and it is in shared instance directory. For example, if your shared instance mount point is /db2sd, then this file should be in /db2sd/db2psc/sqllib_shared/cfg/instancedef.reg. When you run db2greg – dump, you get the output from /var/db2/global.reg and db2hareg -dump output comes from /sqllib_shared/cfg/instancedef.reg. These files are managed by db2.
IBM Flash V9000 – My favorite storage for pureScale

I have been working in DB2 pureScale since original version DB2 9.8. Billions of gallons of water has flown since in river Hudson. DB2 pureScale is one of the best IBM technologies and I am very passionate about this. Not a week passes by, when I am not involved in some kind of pureScale work. The technology is getting newer functionality through new fix packs or new release.
You should test information given in this article in your test environment to gain an experience first. It is not a good idea to experiment this in your production cluster, if you encounter an error and need to fix it. No matter how clearer I can be in my instructions, you should always take things with a grain of salt and not trust it unless you do your own test. May be, I am that way and I like to test things out before making a judgement if this would work or not.
Chicago River – One cold day in December 2015
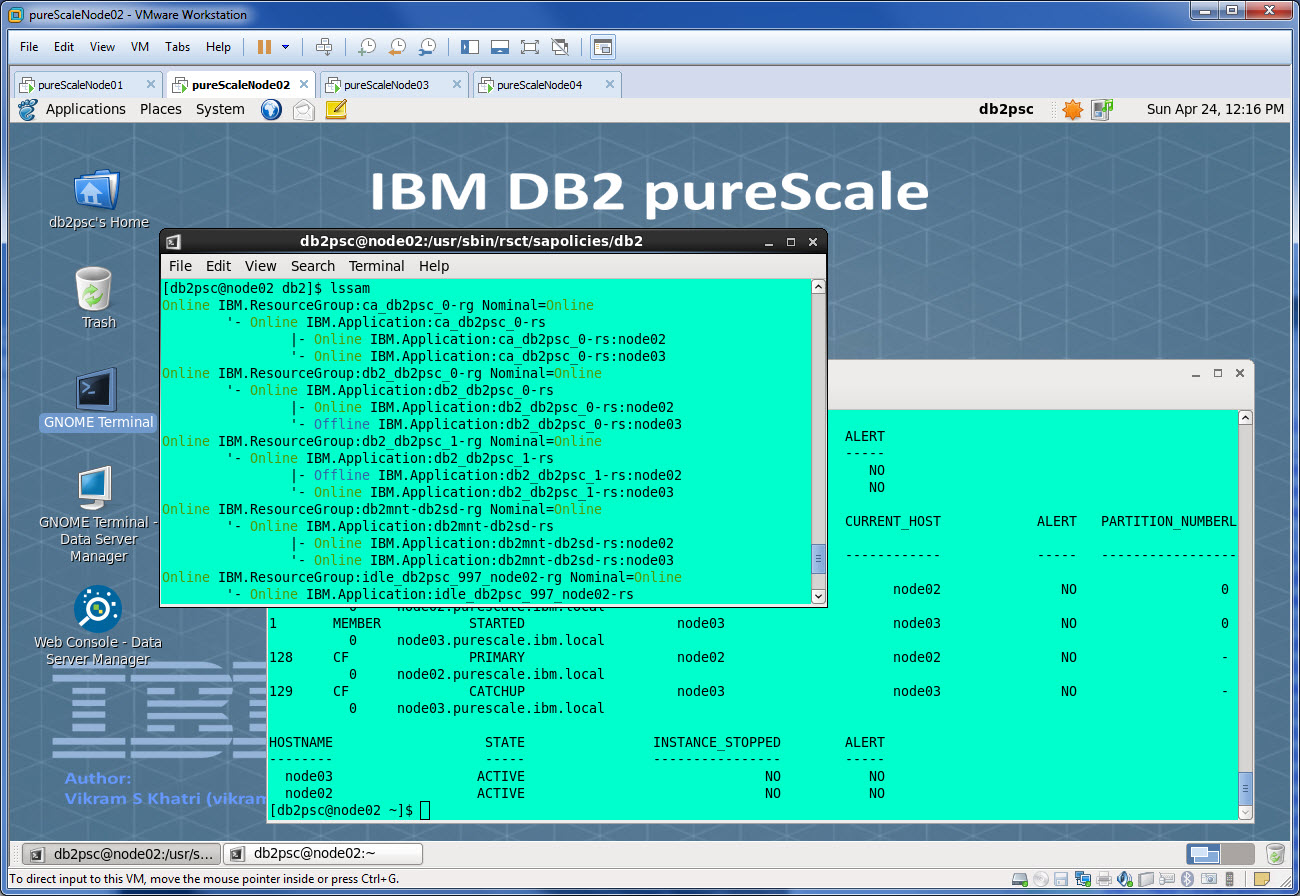
Assume that your db2start is failing or one of the member is not starting and you need a quick fix.
The quick fix assumes that you have all hosts up and running and you have a last good working copy of global.reg, instancedef.reg and netmon.cf. Since you are going to rebuild the cluster TSA resources, an outage will be required and follow this procedure.
All commands prefixed with # assumes to be run as root and $ with instance owner.
# export CT_MANAGEMENT_SCOPE=2 # lsrpdomain --> find out domain name # rmrpdomain -f <domainName>
Save files /var/ct/cfg/netmon.cf and /var/ct/cfg/trace.conf as the following command will reset all RSCT configuration.
For example:
# cp /var/ct/cfg/netmon.cf /tmp/netmon.cf.`hostname -s` # cp /var/ct/cfg/trace.conf /tmp/trace.conf.`hostname -s`
And, repeat above command on all hosts before running the following command.
# /usr/sbin/rsct/install/bin/recfgct –> On all hosts
Restore netmon.cf and trace.conf files. Repeat following on all hosts.
# cp /tmp/netmon.cf.`hostname -s`/var/ct/cfg/netmon.cf# cp /tmp/trace.conf.hostname -s/var/ct/cfg/trace.conf
Reboot all hosts. –> Do not ignore this.
Run this on all hosts to exchange keys for communication assuming that you have names of nodes as node02 and node03.
# preprpnode node02 node03 –> On all hosts and include names of all hosts
From one host:
# export CT_MANAGEMENT_SCOPE=2 # mkrpdomain db2domain node02 node03 <Add names of all hosts> # startrpdomain db2domain # lsrpdomain # lsrpnode
Make sure that you wait for lsrpnode to show all nodes online on all hosts.
When you run command, db2instance -list, it will result into an error since no resources are defined.
$ db2instance -list
The member, CF, or host information could not be obtained. Verify the cluster manager resources are valid by entering db2cluster -cm -verify -resources. Check the db2diag.log for more information.
$ lssam
lssam: No resource groups defined or cluster is offline!
Alternatively, you can also use db2cluster command to create RSCT domain and add nodes to this. You have to still use preprpnode command to exchange the keys. [Actually – this should be your preferred method that using the RSCT commands as it will take care of things in the right order.]
# db2cluster -cm -create -host node02 -domain db2domain
Use same domain name that was found using lsrpdomain name. And add all other hosts.
# db2clutser -cm -add -host node03
Please note: When you run /usr/sbin/rsct/install/bin/recfgct on all hosts, it will wipe out existing RSCT configuration. The critical file for successful CF start is /var/ct/cfg/netmon.cf and save this file before running this recfgct command on each host.
Run db2clutser -cm -add -host <hostname> on all remaining hosts and run lsrpdomain and lsrpnode on each hosts to make sure that the domain is online and all hosts are online in the domain,
Did you notice that we changed the peer domain name from db2domain_20160419233240 to just db2domain? This change won’t affect starting the db2 but adding / dropping a member or updating the instance will fail since we changed the name of the domain. To fix this, you need to update the name of the peer domain to the correct one that we used.
The following steps are only required if you change the name of the RSCT domain name.
# db2greg -dump # db2greg -updvarrec service=PEER_DOMAIN\!variable=NAME,\ value=db2domain,installpath=-,comment=-
Repeat this on all hosts that are part of the peer domain so that the update of the instance using db2iupdt does not fail.
Stop GPFS domain.
# db2cluster -cfs -stop -all
Once GPFS domain is stopped, change the HostFailureDetectionTime to 4. (This requires GPFS to be stopped.)
# db2cluster -cm -set -option hostfailuredetectiontime -value 4
If for some reason, tie-breaker disk needs to be changed. Get 1 GB disk provisioned to all hosts through your SAN admin. Run lspv command on each hosts to check if it has a PVID or not, which should be same. If the lspv command does not show a PVID, follow the procedure.
Run this command on first host.
# chdev -l hdisk<n> -a pv=yes
Run the following commands on all other hosts.
# rmdev -Rdl hdisk<n> # cfgmgr -v
Set tie-breaker disk.
# db2cluster -cm -set -tiebreaker -disk PVID=<pvid>
Start GPFS domain.
# db2cluster -cfs -start -all
Repair network for GPFS
# db2cluster -cfs -repair -network_resiliency -all
After RSCT domain is created, now it is time to rebuild the resources.
$ db2cluster -cm -repair -resources All cluster configurations have been completed successfully. db2cluster exiting ...
Please note that in order to repair resources correctly, we should have a known working copy of global.reg and db2instance.reg as outlined above. If due to any reason whatsoever, if these files are damaged or updated with some wrong entries, restore these files from you last good file system backup. This will save you lots of time and energy.
After resources are repaired successfully, you can check the output of lssam and match it with the last known output.
Few things to learn:
When you change the RSCT domain name, the entry in global.reg PEER_DOMAIN must be updated to the new name on each host through db2greg command so that future db2iupdt commands to make any change does not fail.
# db2greg -updvarrec service=PEER_DOMAIN\!variable=NAME,value=db2domain,\
installpath=-,comment=-
Since we trashed the RSCT configuration and recreated the new cluster, we must set the host failure detection time to an appropriate value so that it works as expected and future db2iupdt does not also fail. For example:
Check the network adapter settings before changing the host failure detection time .
[root@node02 ~]# lscomg
Name Sensitivity Period Priority Broadcast SourceRouting
NIMPathName NIMParameters Grace MediaType UseForNodeMembership
CG2 4 1 1 Yes Yes -1 (Default) 1 (IP) 1
CG1 4 1 1 Yes Yes -1 (Default) 1 (IP) 1
Change host failure detection time.
# db2cluster -cfs -stop -all
All specified hosts have been stopped successfully.
# db2cluster -cm -set -option HOSTFAILUREDETECTIONTIME -value 4
The host failure detection time has been set to 4 seconds.
Check the network adapter settings after changing the host failure detection time.
# lscomg
Name Sensitivity Period Priority Broadcast SourceRouting
NIMPathName NIMParameters Grace MediaType UseForNodeMembership
CG2 4 0.4 1 Yes Yes 30 1 (IP) 1
CG1 4 0.4 1 Yes Yes 30 1 (IP) 1
pureScale runs better on POWER.
DB2 pureScale is much more than DB2. It is a combination of 4 IBM technologies.
- IBM DB2
- RSCT
- Tivoli System Automation
- General Parallel File System (GPFS) and now known as IBM Spectrum Scale after V4.1
If someone says to you that you do not have to worry about GPFS, TSA and RSCT as they are tightly integrated, do not believe it. You have to know enough so that you can recover from failovers.
Every DBA who likes to call themselves as DB2 pureScale DBA must pass through these tests before saying boldly to their management that they are ready to go in production. If you gain experience in the following, I can guarantee you that your market value will increase by 30-50% and you will have unquestionable job security.
Tests that a DBA must perform after a DB2 pureScale instance is created and your first database is created.
- Create second database and see if you can successfully activate it. You will need DB2_DATABASE_CF_MEMORY knowledge.
- Ask your application folks to run an application. Check if you are getting workload balancing or not. If not, your WLB is not working. The easiest is to check the connections at each member. If a member does not show any connection, WLB did not work. Check enableSysplexWLB connection parameter for Java application and enableWLB for CLI in your db2dsdriver.cfg file.
- While an application is running and getting its workload balanced across all members. Run the following tests for continuous availability. Open a command line window on any of the member and run db2instance -list in a loop to check the state of the cluster.
- Kill db2sysc process on one member and check
- Kill ca-server process on primary CF and check if other CF became primary or not.
- db2stop 128;db2start 128 should switch the role of CF
- Run OS shutdown command on any host and it should get a reboot instead of the shutdown. You can’t shutdown a machine from OS in pureScale.
- Power off db2 member and check the health of the cluster
- Power back on db2 member and check if it integrates automatically in the cluster or not.
- Remove the public network cable from one machine and watch what happens
- Put back the cable and check if cluster recovers or not
- Shutdown network interface by using ifdown eth0 command and watch what happens.
- Bring network interface again and watch the recovery process
- Pull the SAN fiber cable from one port and it should not affect the cluster
- Pull the SAN cable from other port and GPFS should panic and watch the cluster status
- Put back both the SAN cables to both ports and watch the cluster recovery. It should be all automatic.
- If you have 2 switch configuration for private and public network, power down one switch and it should not affect anything.
- If you have two switch for SAN, power down one and it should not impact anything.
- Power down any of CF and it should not impact anything.
- Power it up and it should integrate automatically in cluster
- Run online backup from any DB2 member and while backup is happening, power down other db2 member and it should come back up automatically.
- Power down the whole system including SAN, network switches, all hosts
- Power up whole system again including network, SAN and hosts and db2 pureScale should come up automatically including starting of the db2 instance.
- How to bring a host into maintenance for system update
- How to bring a host into maintenance for db2 online fix pack upgarde
- How to upgrade all hosts online for fixpack upgrade
- How to check installed and running versions of TSA, RSCT, GPFS and DB2
- How to commit the online update.
- Take an offline backup and restore it on regular DB2 ESE
- Take an offline backup on DB2 ESE and restore it on pureScale
- Add a member online
- Add another network adapter to a DB2 member or CF without cluster outage but taking a hosts into maintenance and then bringing it back to the cluster
- How to drop a member or CF (Cluster outage required)
- How to extend the GPFS file system by adding another disk to the file system and then rebalancing the data
- How to save crucial TSA and GPFS information for the future recovery
- Practice repair of TSA resources
- If you are using RDMA, how to switch to socket communication. Tip: Use registry variable DB2_CA_TRANSPORT_METHOD=SOCKETS even if DBM CFG CF_TRANSPORT_METHOD is set to RDMA.
- How to check if RDMA is being used actually or not? Tip :
grep -iE 'PsOpen|PsConnect' db2diag.log
Once you do all of the above tests and procedures, you can then have your job security. Do not mess with your job and put your foot down before you say that you are ready unless you have done above in your own and company’s good interests.
I have worked with thousands of customers and I used to think that POWER is no different than Intel platform and I really did not believe that db2 on POWER takes less number of CPU than other databases until I did this test myself with a customer. We replaced famous RED database with DB2 and we were using 1/2 vCPU using same workload without sacrificing the performance. Since then, I am working on POWER more than ever before after realizing its strengths. Of course, it feels better when you drive a premium car.
IBM DB2 pureScale career is much more rewarding than any other DBA career. I say this due to my experience. You get paid well and once you know it well, you can’t be replaced.