You are trying to figure out the best approach to do the case in-sensitive search in DB2. You must first read these 3 excellent articles written on this topic by 3 IBMers.
In a nutshell, you can take one of the approach as outlined below:
- Create a generated column in DB2 using LOWER or UPPER function
CREATE TABLE testtable (name VARCHAR(60), name_lower GENERATED ALWAYS AS (LOWER(name))) CREATE INDEX ix1_name ON testtable (name_lower) SELECT name FROM testtable WHERE LOWER(name) = 'babbu';
DB2 optimizer will actually use index ix1_name when you use LOWER function on name in your query. Please do not consider this to be an all out alternative of Oracle functional index in DB2. DB2 is smart enough for most of the functions where a functional index is not required and I will explain that in detail in some other article with actual examples. The Oracle DBAs get blind sided on this to create generated columns for an alternative of Oracle’s functional indexes.
- Use index extensions
Please read Knut’s article on how to use index extension capability. This approach requires using Kunt’s user defined functions to use index extension capability with the use of DISTINCT TYPE data type. The use of GENERATED COLUMN requires additional storage in table but index extension approach takes that storage in index rather than in the actual table. This will be very useful when adding a GENERATED COLUMN is not a possibility due to page size. - Use COLLATION_KEY_BIT function
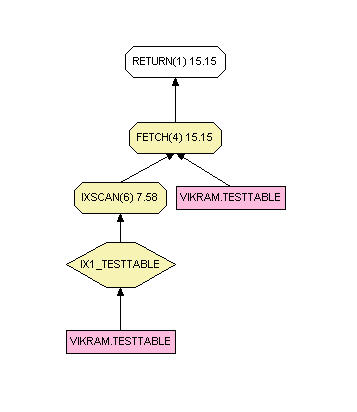
Please refer to Doug’s article on a user defined function and what he described was implemented in DB2 and the DB2 function name is COLLATION_KEY_BIT.SELECT name FROM testtable WHERE collation_key_bit(name,'UCA400R1_S1') = COLLATION_KEY_BIT('babbu', 'UCA400R1_S1');
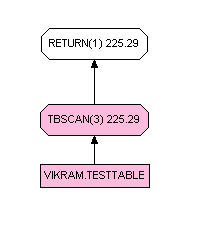
If there is an index on a generated column collation_key_bit(name,’UCA400R1_S1′), DB2 will use the index as shown above otherwise it will use full table scan as shown below. You also get same behavior with the use of LOWER or UPPER function but using COLLATION_KEY_BIT function gives you much greater flexibility in comparing the strings particularly if you want to eliminate accent characters in comparison or to do culturally correct comparisons. For example, Nuernberg should match with Nürnberg. You will not get that with lower or upper function.
You can create a case insensitive database similar to the lines of collation_key_bit function to compare strings properly but let database do that comparison instead of using COLLATION_KEY_BIT function.
$ db2 CREATE DB SAMPLE COLLATE USING UCA500R1_S2 $ db2 create database mydb2 collate using UCA500R1_E0_S1 This is case sensitive but accent insensitive and will collate "role" = "rôle" < "Role" $ db2 create database mydb2 collate using UCA500R1_S1 This is both case and accent insensitive and will collate "role" = "Role" = "rôle"
If you are on DB2 9.5 or later, you can use this collation for case in-sensitive search.
create database mydb2C automatic storage yes on /db2fs USING CODESET UTF-8 TERRITORY US COLLATE USING UCA500R1_LEN_S1_NX pagesize 16384 autoconfigure apply none ;
You will notice some performance impact due to above since SYSTEM or IDENTITY collation gives the best performance.
Which approach you should take - It really depends upon pros and cons of different approaches as outlined above. If you can define all of your STRING data in all tables with a common DISTINCT TYPE and performance is the criteria and you can not use generated columns, go with the index extension approach as per Knut's UDFs. For simplicity, go with case in-sensitive database but be prepared to sacrifice some performance due to complex UCA algorithm of string compare.
The choice is yours.